SIMD optimization
Add comment!September 22nd, 2010
Fifteen years ago, it would be impossible to make a graphics-intensive game without using hand-written assembly language. Almost all classic games used it extensively, including Doom, Marathon and Prince of Persia. That has all changed with modern optimizing compilers and complicated CPUs. Now, writing assembly code by hand hurts performance more often than not, and is largely just used for firmware, drivers and technical stunts in the demoscene. However, there are some assembly language commands that are still useful in modern games, and those are SIMD instructions.
What are SIMD instructions?
SIMD stands for "single instruction, multiple data", and the commands do just that -- with a single instruction, the CPU processes multiple pieces of data. To see why this is useful, consider adding two vectors that each contain four 32-bit variables. Let's call the vectors A and B. Normally you would have to do something like this:
A[0] = A[0] + B[0]; A[1] = A[1] + B[1]; A[2] = A[2] + B[2]; A[3] = A[3] + B[3];However, if you have a SIMD instruction for multiple-add, you can replace it all with a single instruction like this:
A = multiple_add(A, B);At first this just seems like a standard function call. Surely it compiles down to the same thing as the first example, right? However, this isn't a standard function call; it's an assembly language instruction telling the CPU to use its SIMD hardware to add all four of the 32-bit variables in one cycle. If you time it, the SIMD version actually is about three or four times faster.
SIMD in Overgrowth
I usually like to save optimizations for last, but sometimes it's necessary for continued development. I noticed that I was getting 200 fps while flying around a scene, but it dropped to 40 fps when I had the two characters in-game. This would clearly become a problem if I wanted to test out group AI with a larger number of characters, so I decided to try to speed it up. I suspected the CPU was the bottleneck, so I tried profiling using the free open-source profiler called Very Sleepy. I found a few easy bottlenecks and fixed those, and then came across a harder one -- the character skinning function was taking 20% of the CPU time.
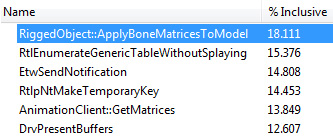
This function handles deforming the character mesh based on its underlying skeleton. This means for each vertex it blends the matrices of each bone that affects it, and then applies the final blended matrix to the vertex. Here is how that looks in pseudocode:
for(each vertex) {
matrix total_matrix = {0,0,...0,0};
for(each attached bone) {
total_matrix += bone.matrix * bone.weight
}
transformed_vertex = total_matrix * vertex
}
To speed this up, I took the bottom-up approach: optimizing the heaviest (most CPU-intensive) components. The first heavy component is "total_matrix += bone.matrix", adding two matrices together. In Overgrowth, 4x4 matrices are implemented as a class that contains 16 components in a single float array.
class mat4 {
float entries[16];
};
The matrix addition function just adds each entry one at a time:
void mat4::operator+=(const mat4 & rhs)
{
entries[0] += rhs.entries[0];
entries[1] += rhs.entries[1];
entries[2] += rhs.entries[2];
...
entries[14] += rhs.entries[14];
entries[15] += rhs.entries[15];
}
Because this function applies the same operations to many different pieces of data, it seemed like a great candidate for SIMD optimization. The most widely-available SIMD instructions on our target platforms (Mac, Windows, Linux) are Intel's SSE instructions, so I decided to use those. They can be most easily used via 'intrinsics', which are very thin wrappers over the assembly instructions. To get started, I created a simple SIMD version of the matrix class:
class simd_mat4 {
__m128 col[4];
};
The __m128 type is a 128-bit variables that contains four 32-bit floats packed together, so I used one to store each column of the 4x4 matrix. Next, I wrote the new SIMD addition function:
void operator+=(const simd_mat4 &other){
col[0] = _mm_add_ps(col[0], other.col[0]);
col[1] = _mm_add_ps(col[1], other.col[1]);
col[2] = _mm_add_ps(col[2], other.col[2]);
col[3] = _mm_add_ps(col[3], other.col[3]);
}
The syntax for these intrinsics is pretty ugly, but they are mostly straightforward. The intrinsic _mm_add_ps just adds two sets of four packed floats together. After writing all the relevant simd_mat4 functions, I changed the character skinning function to convert the mat4s to simd_mat4s before doing the heavy lifting:
for(each bone) {
bone.simd_matrix = simd_matrix(bone.matrix)
}
for(each vertex) {
simd_matrix total_matrix = {0,0,...0,0};
for(each attached bone) {
total_matrix += bone.simd_matrix * bone.weight
}
transformed_vertex = total_matrix * vertex
}
It worked! After profiling again, I found that the function was running a bit over twice as fast as it was before.
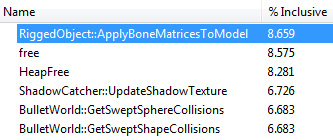
Combined with the other optimizations I made, I now get about 120 frames per second instead of 40. This is still nowhere close to the final shipping level of optimization, but it should be enough for now. Do you have any questions about SIMD instructions, or ideas about how to use them better?